Here we are going to implement the parts of the model MetNet from "MetNet: A Neural Weather Model for Precipitation Forecasting"
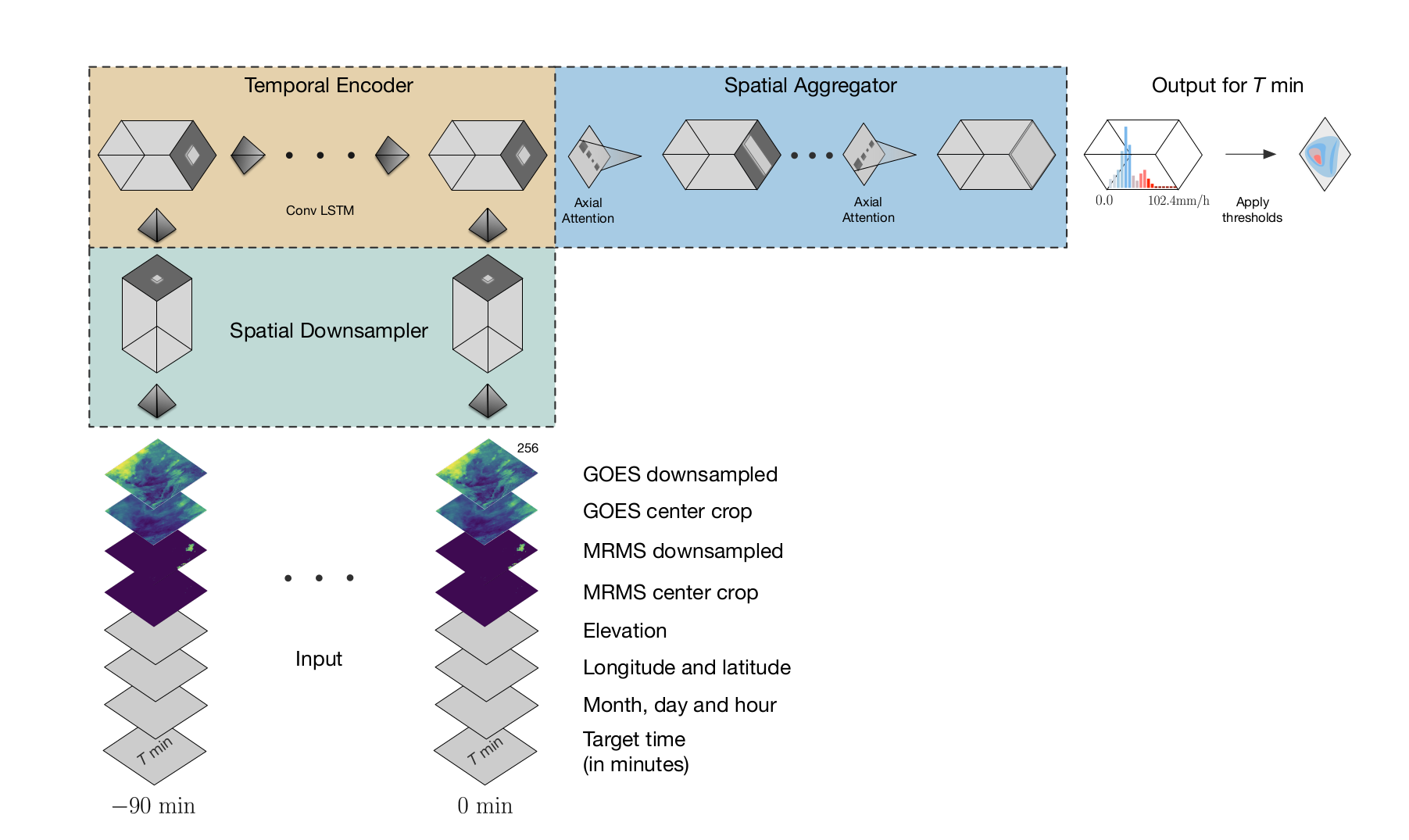
from the paper, the downsampler blocks are a bunch of convs and maxpooling layers, with out anything fancy, not even activations. From the paper:
MetNet aims at fully capturing the spatial context in the input patch. A trade-off arises between the fidelity of the representation and the memory and computation required to compute it. To maintain viable memory and computation requirements, the first part of MetNet contracts the input tensor spatially using a series of convolution and pooling layers. The t slices along the time dimension of the input patch are processed separately. Each slice is first packaged into an input tensor of spatial dimensions 256 × 256 (see Appendix A for the exact pre-processing operations). Each slice is then processed by the following neural network layers:a 3 × 3 convolution with 160 channels, a 2 × 2max-pooling layer with stride 2, three more 3 × 3 convolutions with 256 channels and one more 2 × 2 max pooling layer with stride 2. These operations produce t tensors of spatial dimensions 64 × 64 and 256 channels.
I put less convs and added nn.BatchNorm2d, as I finally ended up using another image encoder, you can choose anything form torchvision or timm
ds = DownSampler(3)
test_eq(ds(torch.rand(2, 3, 256, 256)).shape,[2, 256, 64, 64])
as we can check, it divides by four the spatial resolution,
The second part of MetNet encodes the input patch along the temporal dimension. The spatially contracted slices are given to a recurrent neural network following the order of time. We use a Convolutional Long Short-Term Memory network with kernel size 3×3 and 384 channels for the temporal encoding (Xingjian et al., 2015).
The result is a single tensor of size 64×64 and 384 channels, where each location summarizes spatially and temporally one region of the large contextin the input patch
te = TemporalEncoder(4, 8, n_layers=1)
x,h = te(torch.rand(2, 10, 4, 12, 12))
test_eq(h.shape, [2,8,12,12])
test_eq(x.shape, [2,10,8,12,12])
The leadtime is represented as an integeri= (Ty/2)−1indicating minutes from 2 to 480. The integeriis tiled along thew×hlocations in the patch and is represented as an all-zero vector with a 1at positioniin the vector. By changing the target lead time given as input, one can use the sameMetNet model to make forecasts for the entire range of target times that MetNet is trained on
seq_len=5
i=3
times = (torch.eye(seq_len)[i-1]).float().unsqueeze(-1).unsqueeze(-1)
ones = torch.ones(1,2,2)
times.shape, ones.shape
res = times * ones
res
Beware, from i=0 to i=seq_len-1
x = torch.rand(3,5,2,8,8)
i = 13
ct = condition_time(x, i, (12,16), seq_len=15)
assert ct[i, :,:].sum() == 12*16 #full of ones
ct.shape, ct[:, 0,0]
ct = ConditionTime(3)
x = torch.rand(1,5,2,4,4)
y = ct(x, 1)
y.shape
x = torch.rand(2,4,10)
feat2image(x, target_size=(16,16)).shape
To make MetNet’s receptive field cover the full global spatial context in the input patch, the third part of MetNet uses a series of eight axial self-attention blocks (Ho et al., 2019; Donahue and Si- monyan, 2019). Four axial self-attention blocks operating along the width and four blocks operating along the height are interleaved and have 2048 channels and 16 attention heads each
please install using pip:
pip install axial_attention
attn = AxialAttention(
dim = 16, # embedding dimension
dim_index = 1, # where is the embedding dimension
heads = 8, # number of heads for multi-head attention
num_dimensions = 2, # number of axial dimensions (images is 2, video is 3, or more)
)
x = torch.rand(2, 16, 64, 64)
test_eq(attn(x).shape, x.shape)
We will build a small model to try the concept first.
- The model will output all timesteps up to
horizon. - We can condition on time before passing the images or after (saving some computations)
- To start, we will output a timeseries, so we will put a
headthat generates one value per timestep. If you don't put anyheadyou get the full attention maps.
The params are as following:
image_encoder: A image 2 feature model, can be a VGG for instance.hidden_dim: The channels on the temporal encoder ConvGRU cell.ks: kernel size on the ConvGRU cell.n_layers: Number of ConvGRU cells.n_att_layers: Number of AxialAttention layers on the Temporal Aggregator.ct_first: If we condition time before or after image encoding.head: The head output of the model.horizon: How many timesteps to predict.n_feats: How many features are we passing to the model besides images, they will be encoded as image layers. See appendix of paper.p: Dropout on temporal encoder.debug: If True, prints every intermediary step
The model is structured with a encode_timestep method to condition on each timestep the input images:
- First we take the input image sequence and condition on lead time
- We pass this augmented image trhough the image_encoder
- We apply the temporal encoder and
- Finally we do the spatial attention.
In the forward method:
- We encode the numerical features on image channels using
feat2image - We stack these with the original image
- We iteratively call the
encode_timestepand finally we return the predicted vector
Let's check:
horizon = 5
n_feats = 4
the image_encoder must take 3 (RGB image) + horizon (for the conditining time) + feats (for the extra data planes added to image)
image_encoder = DownSampler(3+horizon+n_feats)
metnet = MetNet(image_encoder, hidden_dim=128,
ks=3, n_layers=1, horizon=horizon,
head=create_head(128, 1), n_feats=n_feats, debug=True)
timeseries data, could be other thing that is sequential as the images
feats = torch.rand(2, n_feats, 10)
imgs = torch.rand(2, 10, 3, 128, 128)
out = metnet(imgs, feats)
out.shape